AI-Powered Subtitles Using Gemini 2.0

Large Language Models (LLMs) have emerged as powerful tools for transcribing and translating subtitles in record time. Although they are not yet perfect enough to entirely replace human-driven subtitling—particularly when absolute accuracy is important—LLMs offer a remarkably fast and budget-friendly alternative. Whether you’re looking to add subtitles at an early stage while waiting for your final manual version, or you simply want an affordable way to make your media accessible, LLMs can be a game-changer.
Last time, I wrote a post on how to translate subtitles using ChatGPT. It’s now 2025, and there have been significant improvements in LLMs from different players. OpenAI’s o1, Claude 3.5 Sonnet, Google's Gemini 2.0, and many other models came out, and they brought substantial improvements in context window size, multimodal capabilities, and better reasoning skills. These advancements allow us to translate subtitles directly from a video with high quality. So, I wanted to write this follow-up post.
In this post, I will show you how to transcribe or translate subtitles from a video file using the Gemini API and Python.
If you don’t want to dig into all the details and just need a tool to transcribe and translate subtitles from an HLS video stream, feel free to stop here and check out the tool I created: https://github.com/dohyeondk/sub-tools.
In this article, the code is a simplified version of the project described above. For those interested in the full implementation, the complete code is available in the referenced repository.
What Are Subtitles?
Subtitles are a text version of the audio in a video. They help people who are deaf or hard of hearing understand the content. Here’s an example of what a subtitle file (SRT format) looks like:
1
00:00:00,000 --> 00:00:05,000
Hello, how are you?
2
00:00:05,000 --> 00:00:10,000
I'm fine, thank you.
Gemini 2.0 Flash Thinking Mode
We’re relying on Google’s advanced LLM, Gemini 2.0 Flash—a multimodal system capable of understanding and generating text, images, and audio. Its standout feature is the ability to handle both transcription and translation in a single request directly from an audio file, rather than going through a separate subtitle-to-subtitle step. This direct approach significantly boosts the quality and accuracy of the final subtitles.
Thinking Mode delivers even better quality. When I compared subtitles generated by Gemini 2.0 Flash to those produced by Gemini 2.0 Flash Thinking Mode, the former still had some syncing issues, while the Thinking Mode output was nearly perfectly aligned with the audio. For our purposes in this article, using Thinking Mode is crucial.
Gemini 2.0 Flash is also incredibly cost-effective; it’s currently free for up to 1,500 requests, though that may change once the service moves out of beta.
Transcribing Subtitles
You can try it out here on Google’s AI Studio. Upload an audio file, and use the prompt below to transcribe English subtitles. As I mentioned in the previous post, when you instruct LLM to perform a task, the way you phrase your prompt matters, and it directly impacts the resulting quality. Make sure to choose "Gemini 2.0 Flash Thinking" model.
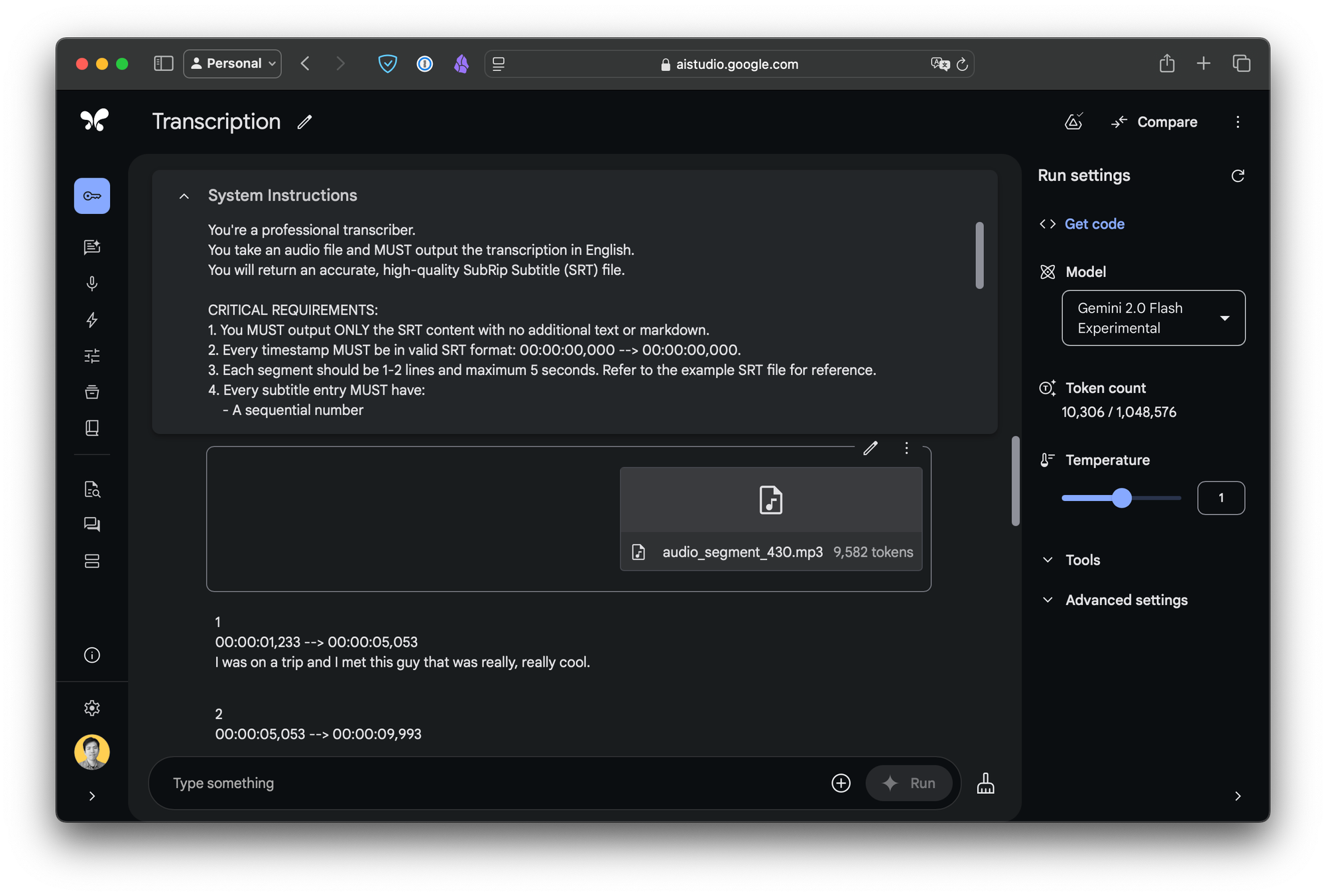
Here's the prompt you could use:
You're a professional transcriber.
You take an audio file and MUST output the transcription in English.
You will return an accurate, high-quality SubRip Subtitle (SRT) file.
CRITICAL REQUIREMENTS:
1. You MUST output ONLY the SRT content with no additional text or markdown.
2. Every timestamp MUST be in valid SRT format: 00:00:00,000 --> 00:00:00,000.
3. Each segment should be 1-2 lines and maximum 5 seconds. Refer to the example SRT file for reference.
4. Every subtitle entry MUST have:
- A sequential number
- A timestamp line
- 1-2 lines of text
- A blank line between entries.
5. The SRT file MUST cover the entire input audio file without missing any content.
6. The SRT file MUST be in the target language.
Timing Guidelines:
- Ensure no timestamp overlaps.
- Always use full timestamp format (00:00:00,000).
- Ensure the timing aligns closely with the spoken words for synchronization.
- Make sure the subtitles cover the entire audio file.
Text Guidelines:
- Use proper punctuation and capitalization.
- Keep original meaning but clean up filler words like "um", "uh", "like", "you know", etc.
- Clean up stutters like "I I I" or "uh uh uh".
- Replace profanity with mild alternatives.
- Include [sound effects] in brackets if applicable.
Here’s the response:
1
00:00:01,233 --> 00:00:05,053
I was on a trip and I met this guy that was really, really cool.
2
00:00:05,053 --> 00:00:09,993
How many of you know what it's like when you meet someone and you just immediately hit it off?
3
00:00:09,993 --> 00:00:12,313
You know, I'm talking about. We just hit it off.
...Awesome! It has the right format, and the timestamps are correct.
Translating Subtitles
Can we use Gemini 2.0 Flash to translate subtitles? Yes, and you can even do it directly from the audio file. Let’s adjust the first three sentences so we can get translated subtitles:
You're a professional transcriber and translater.
You take an audio file and MUST output the transcription in Korean.
You will return an accurate, high-quality SubRip Subtitle (SRT) file.
...
Here’s the response:
1
00:00:00,742 --> 00:00:04,442
여행 중에 정말 멋진
한 남자를 만났어요.
2
00:00:04,772 --> 00:00:08,372
누군가를 만나자마자
마음이 통하는 기분을 아시나요?
...
In the previous post, we translated English subtitles into other languages without adjusting the timestamps. This often caused issues when the translated subtitles had different text lengths, leading to awkwardly large chunks of text appearing in a single block.
What’s great about this approach is that the timestamps are intelligently optimized, resulting in more natural timing based on the content and sync duration. As seen in the example above, the number of subtitle blocks varies depending on the language (3 vs. 2), and the timestamps are adjusted accordingly. This approach provides a more seamless viewing experience tailored to each language.
Pipeline
That’s great! However, it’s important to note that the maximum audio length you can process is around 8-10 minutes, as Gemini 2.0 Flash has an output limit of approximately 8,000 tokens.
If you need to transcribe longer audio files, you’ll have to split them into smaller chunks. Since manually splitting audio can be tedious, let’s automate the process using Python. Here’s a potential pipeline we can consider:
- Extract audio
- Split audio
- Transcribe the audio segments
- Validate the subtitles
- Combine the subtitles
1. Extract audio
Use ffmpeg convert the video to audio. First, install ffmpeg:
// macOS
brew install ffmpeg
Then convert the video to audio:
ffmpeg -i video.mp4 -vn -c:a libmp3lame audio.mp3
2. Split audio
When splitting longer audio, you don’t want to cut in the middle of a sentence. pydub can detect silence (or non-silence for our use case):
from pydub import AudioSegment, silence
audio = AudioSegment.from_mp3("audio.mp3")
sections = silence.detect_nonsilent(audio)
We could use this function to find ranges so that we could split an audio into audio segments:
def segment_audio(audio_path: str, segment_length: int = 300_000):
# Load audio file
audio = AudioSegment.from_file(audio_path)
total_length = len(audio)
current_position = 0
segments = []
while current_position < total_length:
# Calculate end position for current segment
end_position = min(current_position + segment_length, total_length)
# Find non-silent ranges in current segment
chunk = audio[current_position:end_position]
sections = silence.detect_nonsilent(
chunk,
min_silence_len=200, # 200ms
silence_thresh=-40 # -40 dB
)
if sections and len(sections) > 0:
# Add segment using first and last non-silent positions
start = current_position + sections[0][0]
end = current_position + sections[-1][1]
segments.append((start, end))
current_position = end_position
return segments
We also want to ensure each segment is at most five minutes long. After this, now you have MP3 files that are each five minutes or less.
3. Transcribe the audio segments
Next, transcribe or translate the audio segments. Here’s a sample using the google-genai library:
from google import genai
async def audio_to_subtitles(api_key: str, audio_path: str, language: str) -> str:
# Initialize Gemini client
client = genai.Client(api_key=api_key)
# Upload audio file
file = await client.aio.files.upload(path=audio_path)
# Define the system instructions
instructions = f"""
You're a professional transcriber and translator working specifically with {language} as the target language.
You take an audio file and MUST output the transcription in {language}.
You will return an accurate, high-quality SubRip Subtitle (SRT) file.
CRITICAL REQUIREMENTS:
1. You MUST output ONLY the SRT content in {language}, with no additional text or markdown.
2. Every timestamp MUST be in valid SRT format: 00:00:00,000 --> 00:00:00,000.
3. Each segment should be 1-2 lines and maximum 5 seconds. Refer to the example SRT file for reference.
- Do not just decrease the end timestamp to fit within 5 seconds without splitting the text.
- When you split a sentence into multiple segments, make sure the timestamps are correct.
4. Every subtitle entry MUST have:
- A sequential number
- A timestamp line
- 1-2 lines of text
- A blank line between entries.
5. The SRT file MUST cover the entire input audio file without missing any content.
6. The SRT file MUST be in the target language.
"""
# Generate subtitles
response = await client.aio.models.generate_content(
model="gemini-2.0-flash-thinking",
contents=[
{"file": file, "mime_type": "audio/mp3"}
],
system_instruction=instructions
)
# Clean up and return subtitles
return response.text.strip()
# Usage example for English:
subtitles = await audio_to_subtitles(
api_key="your_api_key",
audio_path="audio.mp3",
language="English"
)
# Usage example for Korean
subtitles = await audio_to_subtitles(
api_key="your_api_key",
audio_path="audio.mp3",
language="Korean"
)
4. Validate the subtitles
LLMs aren’t perfect. Sometimes they return invalid SRT format or skip content. We should validate:
- Correct format
- Correct language
- No big gaps at the start or end
- Start and end timestamps are properly ordered (start < end)
- No large gaps between blocks
def validate_subtitles(
content: str,
duration: int,
config: ValidateConfig = ValidateConfig(),
) -> None:
try:
subs = _parse_subtitles(content)
_validate_subtitle_count(subs, config.min_subtitles)
_validate_subtitle_durations(subs, config.max_valid_duration)
_validate_time_boundaries(subs, duration, config)
_validate_time_ordering(subs)
_validate_gaps(subs, config.inter_item_gap_threshold)
except SubtitleValidationError as e:
raise
If validation fails, re-transcribe or re-translate that audio segment by running the step 3 again.
5. Combine the subtitles
After you have the subtitles for each segment, combine them into one file. For example, you can use pysrt:
import pysrt
def combine_subtitle_files(subtitle_files: list[str], output_file: str) -> None:
# Create empty subtitle file
combined = pysrt.SubRipFile()
# Add each subtitle file to the combined file
for file in subtitle_files:
current = pysrt.open(file)
combined += current
# Fix subtitle numbering
combined.clean_indexes()
# Save the combined file
combined.save(output_file, encoding="utf-8")
That’s it! We have now transcribed and translated subtitles from a video file using Gemini 2.0 Thinking. Load the video and the subtitles file in a media player like VLC to see them in sync.
Here’s the limitation I’ve discovered so far: during validation, you’ll notice how many retries we end up needing simply because of one or a few small errors in the response—errors that make the entire output unusable. I’m hopeful this will improve once we can fine-tune the Gemini 2.0 Flash model using audio input.
As mentioned, I’ve developed an open-source tool called sub-tools, based on this process. Feel free to check it out, give it a try, and let me know what you think.
I hope this post was helpful and informative. If you have any questions or feedback, feel free to leave a comment below.
Peace! ✌